万博manbext体育官网娱乐网题库由模子公司自行发布-万博manbext体育官网(中国)官方网站登录入口

本文来自微信公众号:AIX财经万博manbext体育官网娱乐网万博manbext体育官网娱乐网,作家:雷晶,剪辑:金玙璠,题图来自:AI生成
大模子行业有一条潜章程:发布会不错迟到,但榜单战报绝弗成缺席。一张漂亮的收成单,还是成了新模子的标配。但这张收成单,到底有若干含金量?
客岁4月,Meta发布Llama 4 Maverick模子,在LMArena(原Chatbot Arena)盲测榜单上以1417分的ELO冲到第二名,仅次于Gemini 2.5 Pro。但很快,学术圈一篇题为The Leaderboard Illusion的论文揭开了内幕:Meta在发布前擅自测试了至少27个模子变体,只公布了推崇最佳的阿谁。信得过交到开辟者手里的开源版块,排名从第2跌到了第32。更调侃的是,Meta提交的“Llama-4-Maverick-03-26-Experimental”自己等于一个为对话作风专诚优化的实践版块,恢复冗长、堆砌神采美艳,当LMArena开启“作风限定”过滤后,它径直从第2名跌到了第5名。
这并非孤例。肖似的“登顶”“屠榜”音问,险些每隔几周就刷一轮。本年5月,阿里通义千问Qwen 3.7-Max冲上全球编程盲测榜单Code Arena第二,在国产模子中排名最靠前;6月,阶跃星辰Step 3.7 Flash模子登上Artificial Analysis榜单输出速率第一,达到409 tokens/s,其他速率联系方针也排在前哨。模子发布必配榜单战报,还是是固定动作。
榜单本应是用户挑选模子最径直的参考,但问题是,榜单排名的实在度正在受到质疑。
一个模子的推出,频频伴跟着“榜单前几”“才调接近国外头部模子水平”这类话术来背书,用户的本色感受却是:各家模子的分数越来越高,“谁更好用”这个问题反而越来越疲塌。
模子榜单还有参考价值吗?一个模子好不好用,到底该怎么判断?
一、一张榜单是怎么降生的?
咱们先来望望模子的排名是怎么来的。
排名来自“考试”。业内把评估模子性能的测试称为基准测试(Benchmark),这是一套圭臬化的考题,由学术机构、厂商致使个东谈主预计打算,用固定的题目和评分圭臬来熟习模子在特定任务上的推崇。模子作念完测试、拿到分数,再按分数上下排出位次,等于广义上的榜单。
面前的基准测试约莫可分为两种:
一种是离线测试,有一套固定题库,模子作答,系统按圭臬谜底打分。MMLU、GPQA、HumanEval等,走的皆是这条阶梯。这种形貌最大的上风是可量化、可横向比拟。但题库会公开,这也意味着厂商不错提前“背题”。
另一种是在线测试,世俗被称为Arena(竞技场)。莫得固定题目,也莫得圭臬谜底。用户提交一个问题,系统将它同期发给两个匿名模子,用户对比恢复后投票选出更好的阿谁,平台再将投票收尾转动为动态排名。
LMArena等于这个赛谈上的主流玩家,由加州大学伯克利分校等机构发起的LMSYS组织创建,多个厂商径直援用其排名手脚模子才调的背书。它最大的上风是逼近真是使用感受,但局限也很光显:用户评判带有主不雅偏好,曾有参议夸耀,用户会倾向于遴荐篇幅更长、“看上去更专科”的恢复。
某好意思企AI出海崇拜东谈主曾小健提到,在中语语境中,榜单和基准测试频繁被同等看待,许多业内东谈主士也不刻意分别。日常相通中这样说问题不大,但严格来说,两者是有互异的:基准测试指的是一套评测任务,恢复的是“怎么测”的问题;而榜单是基于测试收尾生成的排名,措置的是“怎么排”的问题,且有些榜单还会及时或近及时更新,并引入用户投票、模子对战等机制。
肤浅归来,离线测试像高考,有圭臬谜底;在线测试像选秀,靠不雅众投票。在本文中咱们不严格分别这两个见地,但领会“固定考试”和“及时擂台”这两种机制的互异,有助于看懂排名的道理。
搞线路怎么考,还得知谈谁是出题方。面前的离线基准测试按起原约莫分为三类:
一类是学术型,题库由高校或参议机构预计打算,如MMLU、GSM8K等,专科性更强,但更新较慢,部分已趋于弥漫。
第二类是厂商型,题库由模子公司自行发布,如OpenAI的HumanEval(代码才调测试),更逼近本色运用场景,但出题方自己亦然参赛者,客不雅性存疑。
第三类是第三方寂寞型,由寂寞机构出题运营,也由它们通过整合多个维度的评测数据、按权新生成详细评分,如SuperCLUE、LiveBench等。这类测试态度相对中立,但权重树立、评分章程仍由平台自行把控,透明度有限。
知谈了怎么考、谁出问题了,还要知谈这些榜单查考的是什么才调。
离线答题侧重学科常识与基础推理,竞技场盲测侧重对话体验与东谈主类偏好。为了便捷领会,咱们将主流榜单按类型和查考才调作念了梳理。
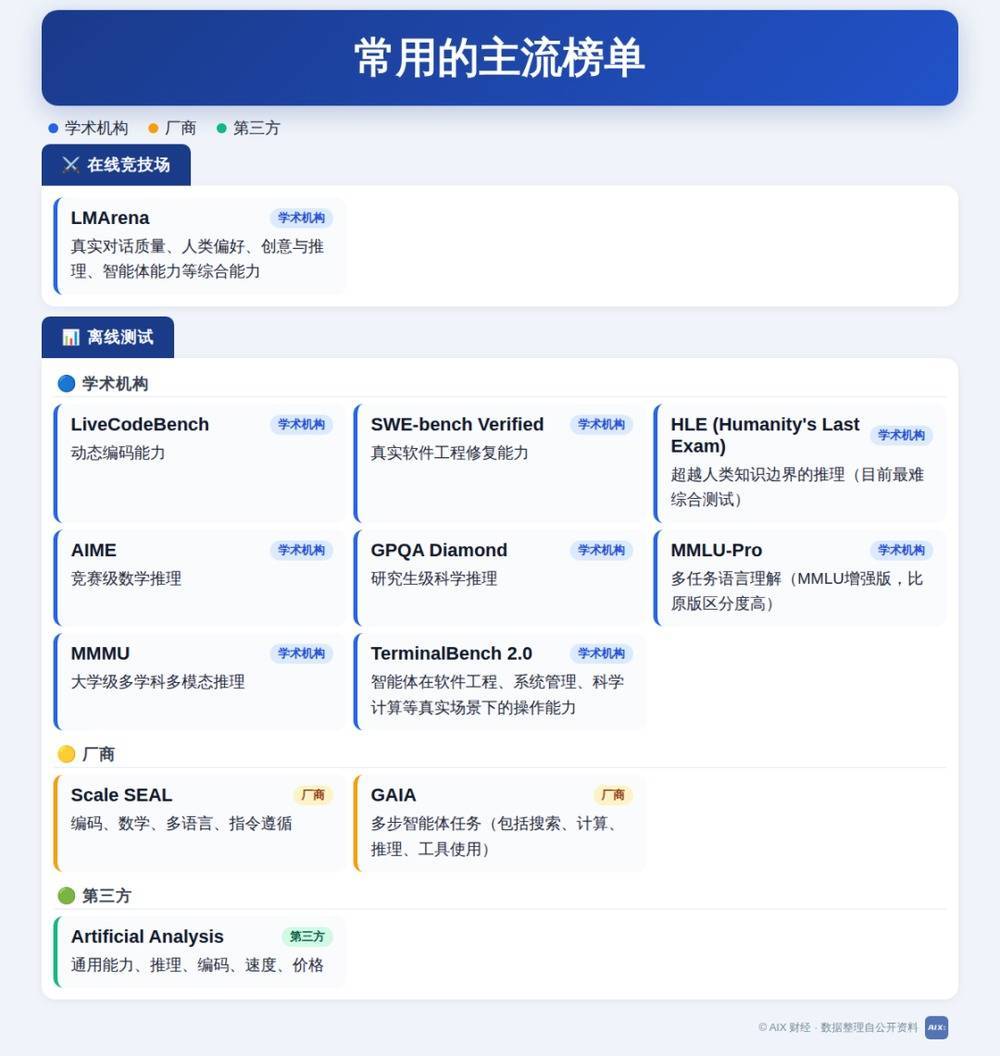
不错看出,念念知谈模子编码才调强不彊不错看LiveCodeBench、SWE-bench verifed等;念念了解推理才调强不彊不错看HLE、MMMU等;念念望望智能体才调则不错望望GAIA、TerminalBench 2.0等榜单。这些亦然面前国内大模子厂商发布模子时最常援用的榜单。
也等于说,选模子的时候,不错先凭证我方关怀的才调“对号入座”。
二、模子榜单也会失真
大模子榜单,本是用户挑选模子最径直的参考,但越来越多东谈主发现,高分选手用起来不一定如预期。
第一个问题是分数通胀。跟着模子才调快速迭代,主流基准测试的“试卷”难度已跟不上模子进化速率,在部分测试中,头部模子的收成集体趋近满分,这样就很丢丑出真是差距。
北京理工大学博士生李岩例如,典型的数学运用问题基准GSM8K,两三年前照旧掂量模子推理才调的紧要圭臬,当今险些通盘主流模子皆能拿到高分,它也就失去了筛选的作用。另一个典型是MMLU,顶级模子的准确率早已冲破90%,趋于弥漫。
第二个问题是刷榜成行业潜章程。面前主流榜单如MMLU、C-Eval等,测试题目与圭臬谜底大多公开,厂商不错赢得到公开的考卷并进行针对性老师。
李岩提到,行业内的刷榜主要分两种:一是用原题或高相似度的改编题老师,要么对标测试原题,要么肤浅修改数据参数,模子止境于“背题考试”;二是考点拆解专项老师,不使用原题,而是拆解试题中枢常识点,合成同类数据老师,肖似“刷模拟卷”。
第三个问题是考题与真是使用场景脱节。面前榜单多为圭臬化试题,侧重常识记念与圭臬谜底匹配,但用户的真是需求远比考题复杂。大模子从业者陈楚提到,模子老师时皆会以榜单高分为办法,但高分不料味着会作念事。在本色业务中,问题不一定有惟一的圭臬谜底,场景也更多元,一个模子是否好用很难单一通过“考试收成”评判。
曾小健打了个比喻,榜单止境于温度计,刷榜止境于在温度计傍边摆了一个火炉,测的本色是火炉的温度,但用户感受到的是通盘房间的体感温度,昭着不会那么高。榜单测的是一个点,用户感受的是通盘场景,当然互异落差。
这三个问题重叠在沿途,就讲解了为什么榜单上的“优等生”,到了真是环境里可能“水土不屈”。
再加上,榜单的公信力曾经有过争议。国内第三方评测机构SuperCLUE在2023年5月发布的评测榜单中,将科大讯飞的星火大模子排在第四位,仅次于Anthropic和OpenAI的两个版块的模子。后被网友发现,它的官网夸耀的护士人排名第一位的是哈工大讯飞聚拢实践室的参议员,榜单收成客不雅性存疑。
是以看榜之前,需要会判断一张榜单是否实在。重心来看两个方面:一是出身,测试套件是否公开透明、是否由模子厂商或盈利机构自行把控。曾小健提到,市面上存在不少“野榜”,有些评测机构自己带有交易化属性,靠出榜单、写软文变现,评测轨范不透明,样本和经过也不公开,宣称某些模子推崇更好,却拿不出令东谈主服气的依据。
二是题库的崭新度,要是主流模子分数无数趋近满分,评释这份试卷还是弥漫,分别度有限。李岩以为,跟着旧数据集徐徐失效,学术界也在握住推出更高难度的测评集,榜单自身的迭代一样在倒逼模子冲破才调瓶颈。
三、什么才是好用的模子?
跟着大模子走向交易落地,榜单排名牵动的利益链条只会更长,围绕榜单的争议也不会住手,那就不仅要会“看”榜单,还要能领会榜单呈现的信息。
面前主流基准测试已细分出数学推理、代码生成、常识问答、长文才能略等多个维度,一个在代码榜单上最初的模子,随机擅长写营销案牍;一个常识问答推崇优异的模子,处理长文档可才调不从心。
这里咱们也凭证主流榜单官网展示的数据,梳理了一些模子排名情况。需要辅导的是,榜单上的数据更新有蔓延,且随时可能有变,面前截取的是放浪发稿的情况,供全球参考。

不错看出,Google的Gemini系列是面前遮蔽面最广的“万能型选手”;OpenAI和Anthropic各有上风,OpenAI的模子推理才调更强、而Anthropic则更擅长任务话语领会。
国内厂商则在特定赛谈上占有一定上风。其中,DeepSeek的V3.2 Speciale和智谱的GLM-4.7均置身LiveCodeBench编码才调榜前五;MiniMax的M3模子参加了GPQA Diamond推理榜;而在视频和图像生成领域,字节最初的 Seedance 2.0、阿里巴巴的HappyHorse1.0、快手的Kling 3.0等国产模子还是成为主力玩家。
更光显的一个趋势是,莫得一个模子大略赢下通盘榜单。要是关注各家厂商的技艺阐发或发布会,会发现一个限定:模子在哪个标的有冲破,就重心展示对应的榜单收成,有些厂商还会在一个详细榜单上单独拎出我方最初的几个子项,用局部上风来佐证举座实力。
这也辅导咱们,不要只看单一榜单的排行,尤其当两款模子分数区间周边时,排名先后险些莫得本色参考价值。与此同期,场景不同,对“好模子”的界说也实足不同,是以要先明确我方的需求,再去找对应领域的榜单,而不是盯着一张详细排行看总分。
是以,看榜单的中枢原则等于:多个起原、多个维度、动态不雅察。选几个不同出处、不同题库的榜单交叉考据,要是论断一致,才更实在。
除了看榜单,该怎么判断一个模子好不好用?
陈楚以为,评估一个模子弗成只看准确性,还要看它靠近无意输入会不会犯错、在生分任务上推崇是否踏实、推理速率和资源耗尽是否可罗致。
他的作念法是先看榜单进行初筛,再凭证我方的使用需求定制相应的基准测试,把新旧模子放在真是环境里并行跑一段时间,看本色效力互异。
关于遍及用户来说,不需要这样复杂,但逻辑是肖似的。李岩提议,不错挑几个我方日常职责中反复出现的任务,如作念PPT、写周报、整理府上等,分别让不同模子跑一遍,并把收尾作念横向对比。此外,关注各式科技媒体的测评亦然一个低资本的参考形貌。
曾小健则以为遍及用户不需要过度参议榜单,按照个东谈主民俗和本色体验使用即可。但对专科从业者,他反复强调真是测试的紧要性,在他看来,榜单只可提供有限参考,更多判断要靠本色业务场景中的测试来考据。
模子能不颖悟好活,还得上手试。先放松候选范围,再把模子放到我方的业务场景中跑任务,看它推崇怎么,这是面前业内的一种共鸣。
(应受访者条款,文中李岩、陈楚为假名。)
本文来自微信公众号:AIX财经,作家:雷晶,剪辑:金玙璠
本文来自微信公众号:AIX财经万博manbext体育官网娱乐网万博manbext体育官网娱乐网,作家:雷晶,剪辑:金玙璠,题图来自:AI生成 大模子行业有一条潜章程:发布会不错迟到,但榜单战报绝弗成缺席。一张漂亮的收成单,还是成了新模子的标配。但这张收成单,到底有若干含金量? 客岁4月,Meta发布Llama 4 Maverick模子,在LMArena(原Chatbot Arena)盲测榜单上以1417分的ELO冲到第二名,仅次于Gemini 2.5 Pro。但很快,学术圈一篇题为The Le
查看更多->
谈交往精髓,林荣追随您成长! 图片 在这个行业,许多东说念主怯生生黑天鹅,怯生生的雄壮的行情,怯生生各式给力的音书面和基本面。而关于交往能手来说,这种行情其实咱们诅咒常心爱的。因为黑天鹅,龙头趋势,好的基本面和音书面,是咱们最大的利润起原。因为这个时分,会催动趋势的大行情的产生,这种逾额的利润时时是大量利润的起原。 图片 图片 如上图,最近股市一派哀鸿遍地,全球指数纷纷呈现了下落的景况,但其实通盘这个词趋势在前一个星期也曾有逆转的迹象。 图片 A股亦然如斯,强势结构的回转特别显然。全球的经济也
查看更多->
谈来去精髓,林荣随同您成长! 图片万博manbext体育官网娱乐网万博manbext体育官网娱乐网 什么是群体共鸣预期?这种意境我称之为大部分东谈主的群体预期。在我心中,最好的的买点即是群体预期,当这种买点产生的时辰,价钱轻轻一推,就容易使价钱产生趋势。价钱的鼓动,需要共鸣智商产生。大部分东谈主买,智商导致价钱推高,这是基本逻辑。 图片 如上图,前边2周的外汇势能,8小时级别以下的势能结构,169和338全部价钱齐在往下去运转,此时8小时级别以下的澳系空头就在迟缓连系。这就叫群体预期,当预期产
查看更多->

